

輝達 Vera CPU 完整拆解:88 核打趴英特爾背後,是 Arm 對 x86 的世紀逆襲,台廠誰受惠?
先講結論:Vera 不只是一顆更快的 CPU,而是輝達(NVIDIA)對整個資料中心心臟下手的訊號。
它是輝達第一顆「從頭自研核心」的處理器,88 顆自家設計的 Olympus 核心,正面對撞英特爾與超微的 x86 地盤。
對台灣散戶來說,重點不是 Vera 多猛,而是它把 Arm 推上資料中心王座的速度,正在重畫一條你手上可能已經有持股的供應鏈。
輝達為什麼不再用現成核心?Vera 是第一顆「真.自研」處理器
前一代的 Grace CPU 是輝達向 Arm 採購的公版設計(Neoverse V2 架構,72 核),就像買了一套現成模組再組裝。
Vera 則是輝達第一次從指令集往上、一路自己蓋到頂:88 顆自家設計、代號 Olympus 的核心架構,相容最新 Arm 指令規範(Armv9.2,可理解為 Arm 架構目前最新世代的能力集),資料來源:NVIDIA 技術部落格,2026 上半年。
差別在哪?
公版核心人人買得到,自研核心只有你有。
輝達把 CPU 從「順便配的零件」升級成「跟 GPU 一起共同設計的戰略武器」。
搭配 NVIDIA 空間多執行緒(Spatial Multithreading)技術,88 核可同時跑到 176 條執行緒,專門對付代理式 AI(Agentic AI)那種延遲敏感、控制密集的任務(資料來源:NVIDIA Vera CPU 產品頁,2026)。
別管核心數了,這顆晶片真正嚇人的地方在這裡
真正的問題不是核心數,是餵不餵得飽。
Vera 配上最高 1.5 TB 的高速 DDR 記憶體(LPDDR5X),總頻寬達 1.2 TB/s,換算每核心約 14 GB/s——對比英特爾 Xeon 6980P 每核約 3.2 GB/s 領先 4.4 倍,對比 AMD EPYC 9575F 每核約 7.2 GB/s 領先 2 倍,綜合平均約 3 倍水準(資料來源:NVIDIA Developer Blog,2026)。
更關鍵的是它跟 GPU 的臍帶。
第二代 NVLink-C2C(NVIDIA 自研的晶片間高速互連,作用像讓 CPU 與 GPU 共用同一塊記憶體的高速公路,不像 PCIe 需要額外的資料搬運成本)把 Vera CPU 與 Rubin GPU 黏成同一個記憶體位址空間,讓 AI 推論時的工作暫存(KV-cache,可理解為模型的「工作暫存區」)與超大資料集幾乎沒有搬運代價。
整顆晶片就是為了 AI 工廠(AI Factory)量身打造(資料來源:Tom’s Hardware、Phoronix,2026)。
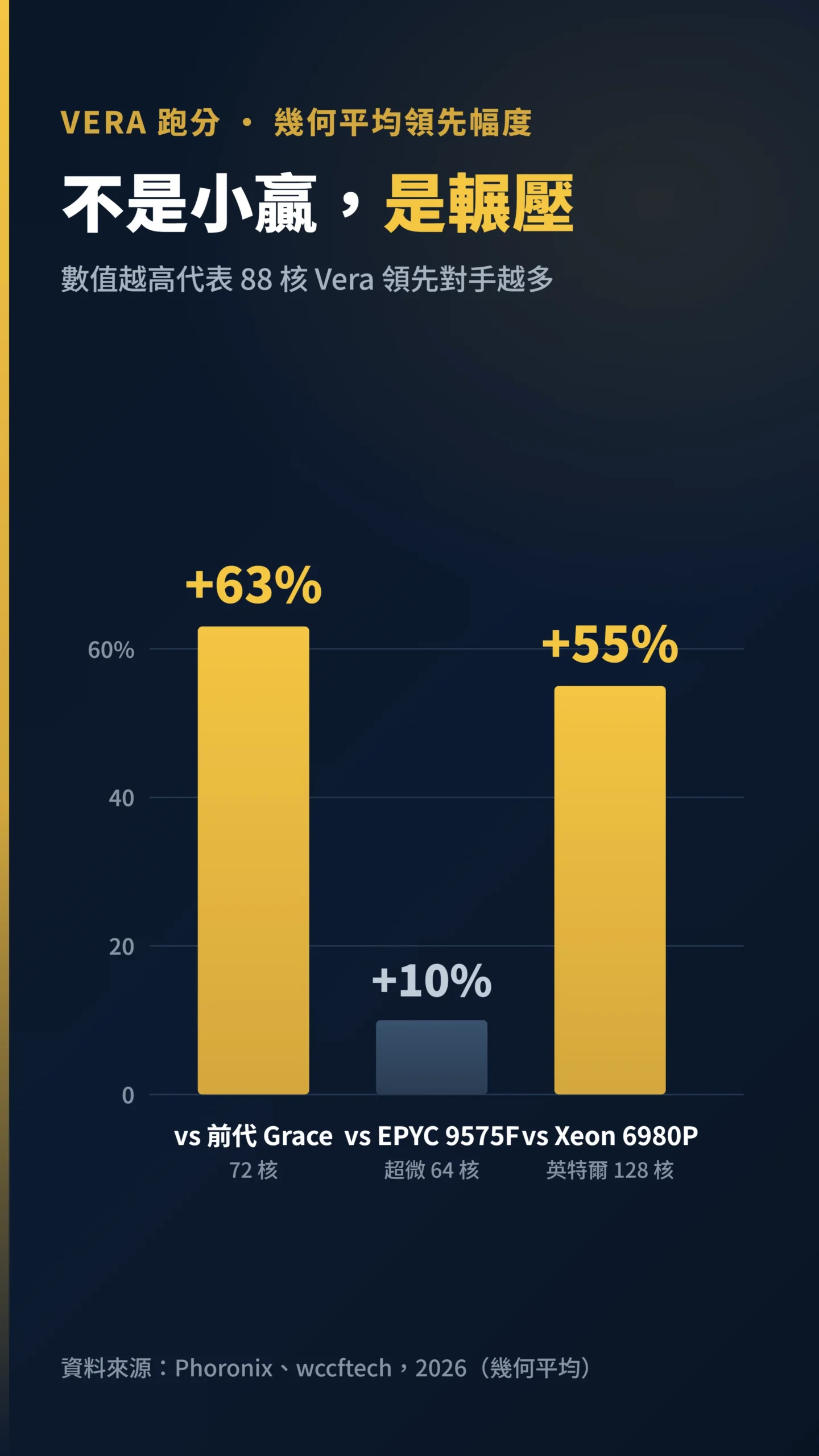
跑分震撼彈:它連 128 核的 Xeon 都電爆 55%
截至 2026 年首批實測,Vera 不是小贏,是輾壓。
根據 Phoronix 與 wccftech 的首發跑分,在所有測項的幾何平均(Geomean,以乘積開根號取代算術平均,避免少數高分測項拉抬整體印象)下:88 核 Vera 比 72 核前代 Grace 快 63%;比超微 64 核 EPYC 9575F 快 10%;比英特爾 128 核 Xeon 6980P 快 55%(資料來源:Phoronix,2026)。
但這裡要替散戶踩一下煞車。
Simakov 等人(2023)在 IWAHPCE-2023 的研究(ACM,Are we ready for broader adoption of ARM in the HPC community)指出,Arm 架構的 Graviton 3 在 Gromacs、OpenFOAM、TensorFlow 等科學計算應用上效能扎實;但在重運算場景仍落後最快的 x86 方案,能源效率則介於 x86 方案之間,整體評估認為 Arm 廣泛進入高效能運算社群是可行的,但不是萬靈丹。
Vera 的成績亮眼,是因為它被輝達綁定在 AI 推論這個它最擅長的戰場,而不是通用運算。
你沒注意到的事:伺服器市場正在發生一場安靜的政變
x86 稱霸伺服器三十年,但現在 Arm 已經吃掉兩成,而且還在加速。
2025 年,x86 仍占資料中心 CPU 市場約一半以上,但 Arm 架構處理器依統計口徑不同,已佔全球伺服器市場的 15% 至 21%(UBS 以收入口徑估算約 15%;部分出貨量口徑統計則高達 21% 以上——兩組數字分母定義不同,不宜直接加總;資料來源:Tom’s Hardware、SemiAnalysis、UBS,2025-2026)。
AWS 自家一半的 CPU 已經是 Arm 的 Graviton。
瑞銀(UBS)預估,到 2030 年前後,Arm 可拿下伺服器 CPU 出貨量的 40% 到 45%,市場規模從 2025 年約 300 億美元膨脹到 2030 年約 1700 億美元(資料來源:UBS 報告轉述,2025)。
Arm 執行長哈斯(Rene Haas)在 2026 年 5 月法說會(Arm FY2026 Q4)直接放話:「到本十年末(by the end of the decade),市占最高的 CPU 架構將會是 Arm。」
「資料中心全年無休運轉,能源已成為一大隱憂;ARM 採用精簡指令集(RISC),天生為更高的能源效率而設計,這正是它從消費裝置一路打進雲端伺服器的關鍵。」— Rahman、Khan & Zaman(2024),Redefining Computing: Rise of ARM from consumer to Cloud for energy efficiency, arXiv:2402.02527.
輝達選 Arm 而不選 x86,本質上是押注「每瓦效能」這條路。
NVIDIA 自己宣稱 Vera 對比 x86 機櫃有 2 倍的每瓦效能、4 倍的部署密度。
當電力變成資料中心最稀缺的資源,這個選擇的份量就懂了。
但有一個沒人想說的對手:你的客戶正在自己做晶片
趨勢分析最容易漏掉的一塊,是 Vera 最直接的替代威脅——那些同時也是它最大客戶的公司,正在自己做晶片。
Google TPU v6(Trillium)、Amazon Trainium 2/3、Microsoft Maia 2、Meta MTIA,這四條自建 ASIC(特殊應用積體電路,也就是「只做你那件事的專用晶片」)路線全部在 2025 到 2026 年陸續落地。
當 Vera Rubin NVL72 一組機櫃的單價持續攀升,雲端巨頭自建 ASIC 的投資回報臨界點就更容易跨越。
這不是說 NVIDIA 會輸,而是說:Vera 的成長天花板,很大程度上取決於雲端巨頭願意把多少推論工作留給外購方案。
這條線現在的進展比多數人預期快,但幾乎沒有出現在主流的 NVIDIA 多頭論述裡。
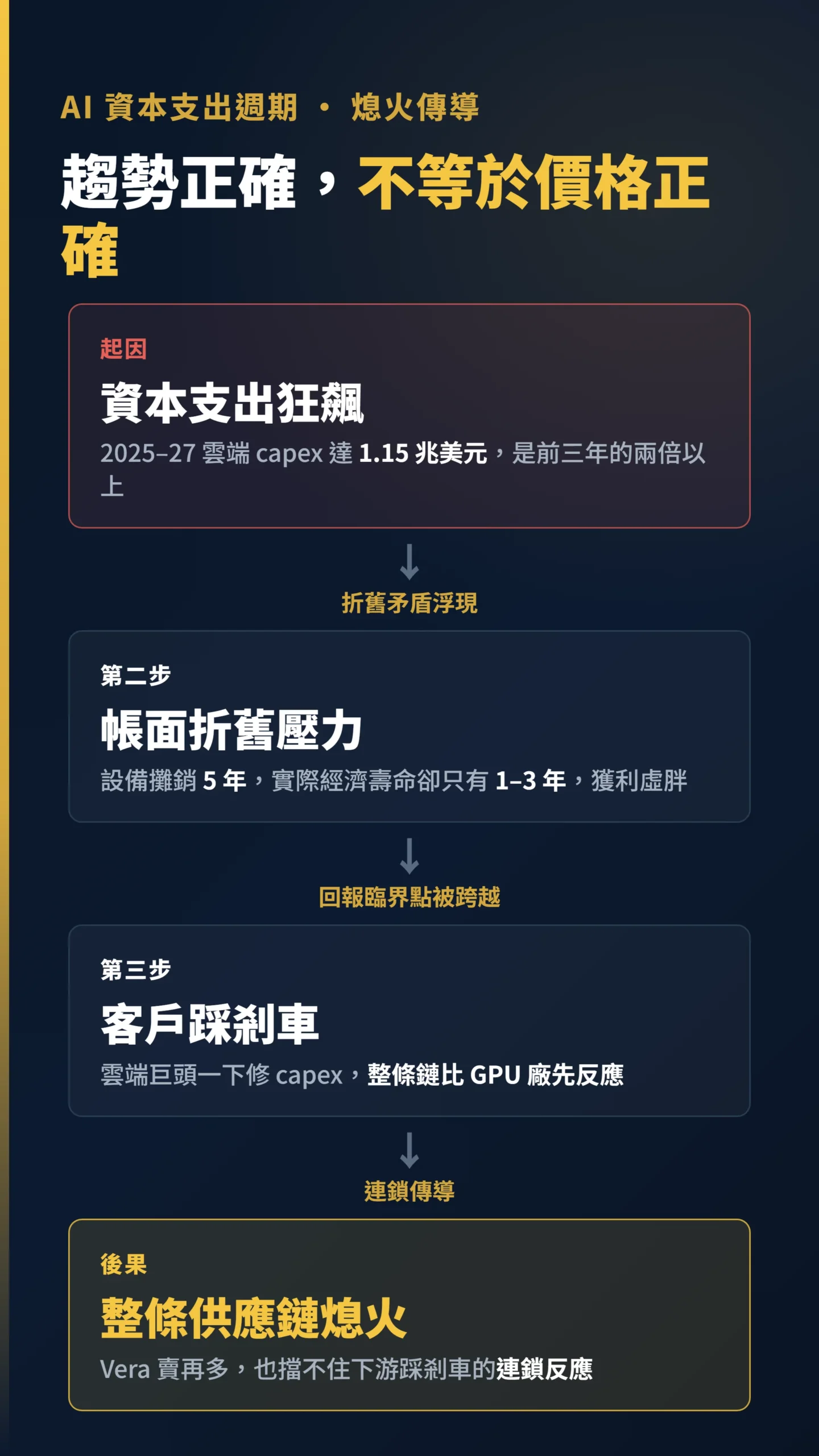
潑冷水時間:Vera 賣再好,AI 資本支出一旦轉向整條鏈就熄火
Vera 幾乎只會跟 Rubin GPU 一起出現在 Vera Rubin NVL72 機櫃裡——一櫃塞 72 顆 Rubin 封裝、36 顆 Vera CPU,推論算力達 3.6 exaFLOPS(NVFP4 4-bit 超低精度推論峰值;若換算為訓練常用的 BF16 精度,實際算力約為前者的 1/4 到 1/8)。
NVL72 已於 2026 年第一季開始量產,客戶端出貨時程為 2026 下半年(資料來源:NVIDIA Newsroom、Tom’s Hardware,2026)。
它的命運跟整個 AI 資本支出週期綁在一起。
台廠 ODM 在這條鏈上能吃到多少,Dell 伺服器那波拆過了,邏輯一樣。
而這個週期,風險正在累積。
高盛預估 2025 到 2027 年超大規模雲端業者的資本支出將達 1.15 兆美元,是 2022 到 2024 年的兩倍以上。
有一個財務矛盾很少人提:雲端業者在帳面上把這些 AI 設備攤銷五年,但對沖基金研究機構 Man Group、Morningstar 等分析師普遍認為 AI 晶片真實的經濟壽命只有一到三年——帳面折舊速度慢,設備換代快,這個差距讓報表上的獲利看起來比實際更漂亮(資料來源:Man Group、Morningstar,2025)。
往更大的圖看:據多家機構試算(Man Group、Morningstar、高盛),若五大雲端巨頭依計畫持續投入 AI 資本支出到 2030 年,每年的帳面折舊壓力將超越它們 2025 年的合計獲利。
歷史上每一次基礎建設大爆發——鐵路、光纖、雲端——幾乎都以「蓋過頭、超額競爭、股價難看」收場。
Vera 賣再多,也擋不住下游客戶若踩剎車的連鎖反應。
給台灣散戶的具體提醒:別只盯著輝達股價
真正跟你錢包有關的,不是 Vera 的核心數,是它整條供應鏈在台灣的落點。
Vera 與 Rubin 由台積電的先進封裝製程製造,其中 CoWoS(一種把多顆晶片疊在同一個封裝基板上的 2.5D 封裝技術)的月產能爬坡速度,才是決定 NVL72 實際出貨節奏的真正瓶頸,比核心數更直接影響台股相關標的。
往上游看,Rubin 系統還需要第四代高頻寬記憶體(HBM4),目前供應高度集中於 SK Hynix(約六至七成市占),Micron 追趕中——HBM4 產能是比 CoWoS 更上游的制約,也是台廠直接參與度相對有限的環節。
液冷散熱系統、電源管理模組、高規格 SOCAMM 記憶體模組以及伺服器 ODM,則大量集中在台廠手上,這條鏈才是台股投資人實際能參與的部位。
在估值面,目前輝達的預估本益比(NTM PE,市場為未來 12 個月每賺 1 元願意付幾元)約落在 35 到 45 倍區間,隱含市場對輝達 2026 到 2028 年 EPS 年複合成長率的期待達 35% 至 40%;EV/Sales(企業價值對營收比)同樣處歷史偏高區間。
這不是說它一定貴,但「趨勢正確」跟「現在的估值合理」是兩件事,散戶最常把這兩件事混為一談。
四個務實提醒。
第一,輝達高估值已把「賣爆」price in 了——市場期待 35-40% 的 EPS 年成長,若實際交出 25-30%,即便仍是強勁成長,股價也可能大幅修正;學術研究一再指出,基礎建設熱潮末段進場的報酬通常難看。
第二,美國出口管制是 NVIDIA 估值最大的外生風險——2025 至 2026 年對 AI 晶片出口管制持續升級,Vera Rubin 若比照或嚴於 H20 晶片受限,中國市場整體受壓,台廠 CoWoS 出貨量也同步縮減,但這個風險幾乎不出現在多頭論述裡。
第三,留意液冷散熱、電源管理、CoWoS 先進封裝、SOCAMM 記憶體模組這類被忽略的二線受惠者——它們的股價相對便宜,散熱族群目前 PE 普遍低於封測族群,估值差距一到兩倍都有,比 GPU 主角的定價理性。
第四,把 AI 資本支出當成景氣指標來追蹤——雲端巨頭一旦下修財測中的 capex 數字,整條鏈會比 GPU 廠先反應。
Vera 是一顆好晶片,Arm 的逆襲也是真的趨勢。
但趨勢正確不等於現在的價格正確。
明天上班可以做一件事:查一下你持股的台廠裡,有多少營收來自 AI 伺服器,下一個財報季毛利率有沒有比上季更好看——那個數字,比 Vera 的核心數更值得盯。
本文為個人觀點分享,不構成任何投資建議。
文中所有數據與預測均來自公開資料,過去表現不代表未來結果。
投資涉及風險,市場價格可能大幅波動,請依個人財務狀況、投資目標與風險承受能力審慎評估,必要時請諮詢具備合法資格的專業財務顧問。
本文不構成買賣任何有價證券之要約、邀請或建議。